Types
Online transaction processing (OLTP) databases These handle a large number of user-facing requests and transactions. Queries are often predefined and short-lived.
Online analytical processing (OLAP) databases These handle complex aggregations. OLAP databases are often used for analytics and data warehousing, and are capable of handling complex, long-running ad hoc queries.
Hybrid transactional and analytical processing (HTAP) These databases combine properties of both OLTP and OLAP stores.
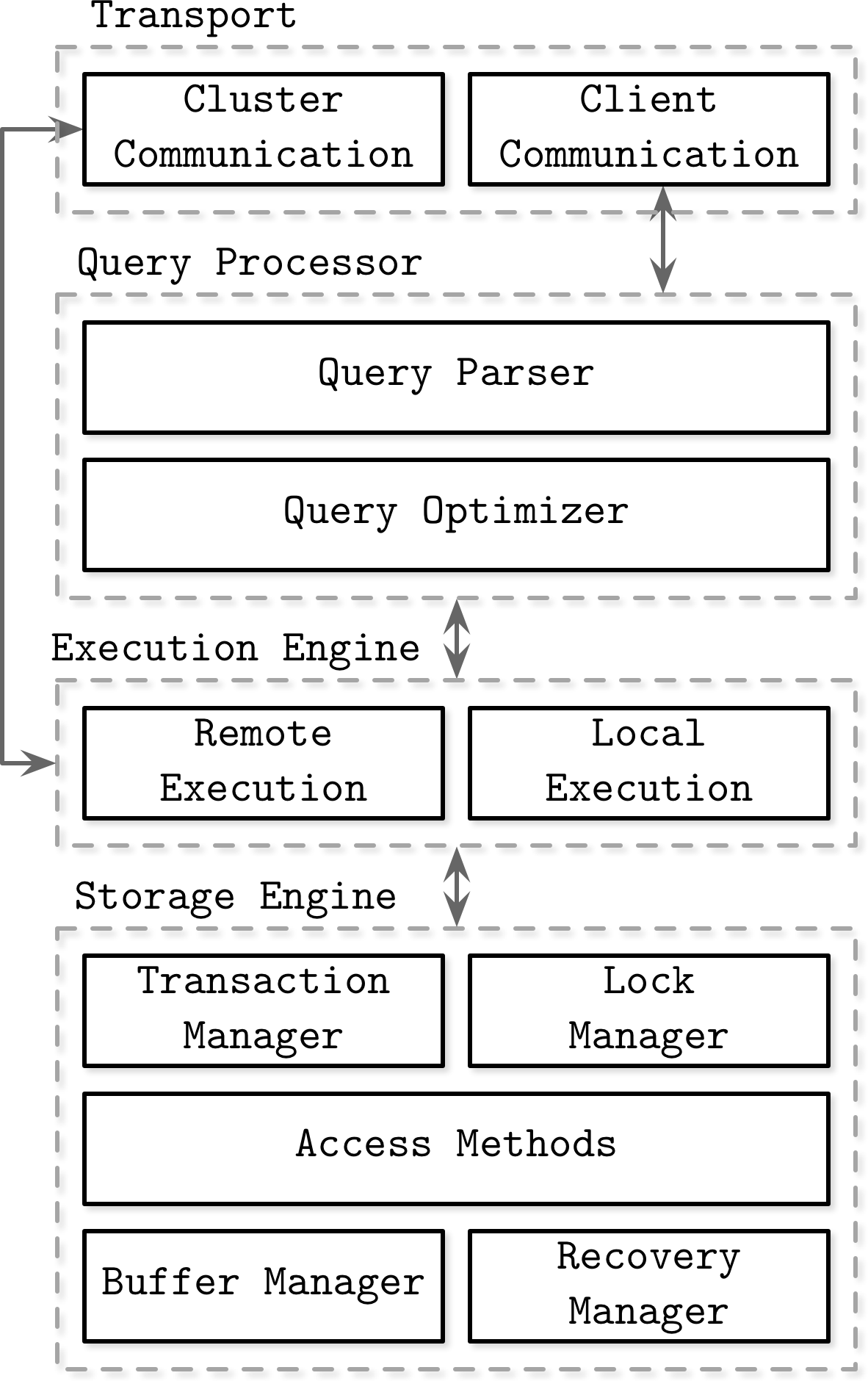
Figure 1-1. Architecture of a database management system
- Descr
Database management systems use a client/server model, where database system instances (nodes) take the role of servers, and application instances take the role of clients.
Client requests arrive through the transport subsystem. Requests come in the form of queries, most often expressed in some query language. The transport subsystem is also responsible for communication with other nodes in the database cluster.
Upon receipt, the transport subsystem hands the query over to a query processor, which parses, interprets, and validates it. Later, access control checks are performed, as they can be done fully only after the query is interpreted.
The parsed query is passed to the query optimizer, which first eliminates impossible and redundant parts of the query, and then attempts to find the most efficient way to execute it based on internal statistics (index cardinality, approximate intersection size, etc.) and data placement (which nodes in the cluster hold the data and the costs associated with its transfer). The optimizer handles both relational operations required for query resolution, usually presented as a dependency tree, and optimizations, such as index ordering, cardinality estimation, and choosing access methods.
The query is usually presented in the form of an execution plan (or query plan): a sequence of operations that have to be carried out for its results to be considered complete. Since the same query can be satisfied using different execution plans that can vary in efficiency, the optimizer picks the best available plan.
The execution plan is carried out by the execution engine, which aggregates the results of local and remote operations. Remote execution can involve writing and reading data to and from other nodes in the cluster, and replication.
Local queries (coming directly from clients or from other nodes) are executed by the storage engine. The storage engine has several components with dedicated responsibilities:
Transaction manager This manager schedules transactions and ensures they cannot leave the database in a logically inconsistent state.
Lock manager This manager locks on the database objects for the running transactions, ensuring that concurrent operations do not violate physical data integrity.
Access methods (storage structures) These manage access and organizing data on disk. Access methods include heap files and storage structures such as B-Trees (see “Ubiquitous B-Trees”) or LSM Trees (see “LSM Trees”).
Buffer manager This manager caches data pages in memory (see “Buffer Management”).
Recovery manager This manager maintains the operation log and restoring the system state in case of a failure (see “Recovery”).
Together, transaction and lock managers are responsible for concurrency control (see “Concurrency Control”): they guarantee logical and physical data integrity while ensuring that concurrent operations are executed as efficiently as possible.
Column versus Row
One of the ways to classify databases is by how the data is stored on disk: row- or column-wise. Tables can be partitioned either horizontally (storing values belonging to the same row together), or vertically (storing values belonging to the same column together)
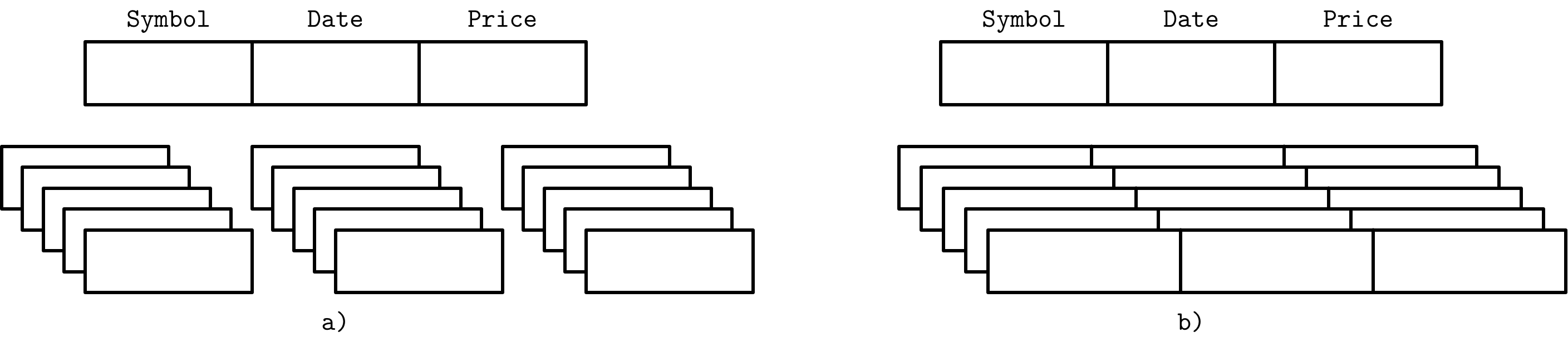
To decide whether to use a column- or a row-oriented store, you need to understand your access patterns. If the read data is consumed in records (i.e., most or all of the columns are requested) and the workload consists mostly of point queries and range scans, the row-oriented approach is likely to yield better results. If scans span many rows, or compute aggregate over a subset of columns, it is worth considering a column-oriented approach.
Index
An index is a structure that organizes data records on disk in a way that facilitates efficient retrieval operations. Index files are organized as specialized structures that map keys to locations in data files where the records identified by these keys (in the case of heap files) or primary keys (in the case of index-organized tables) are stored.
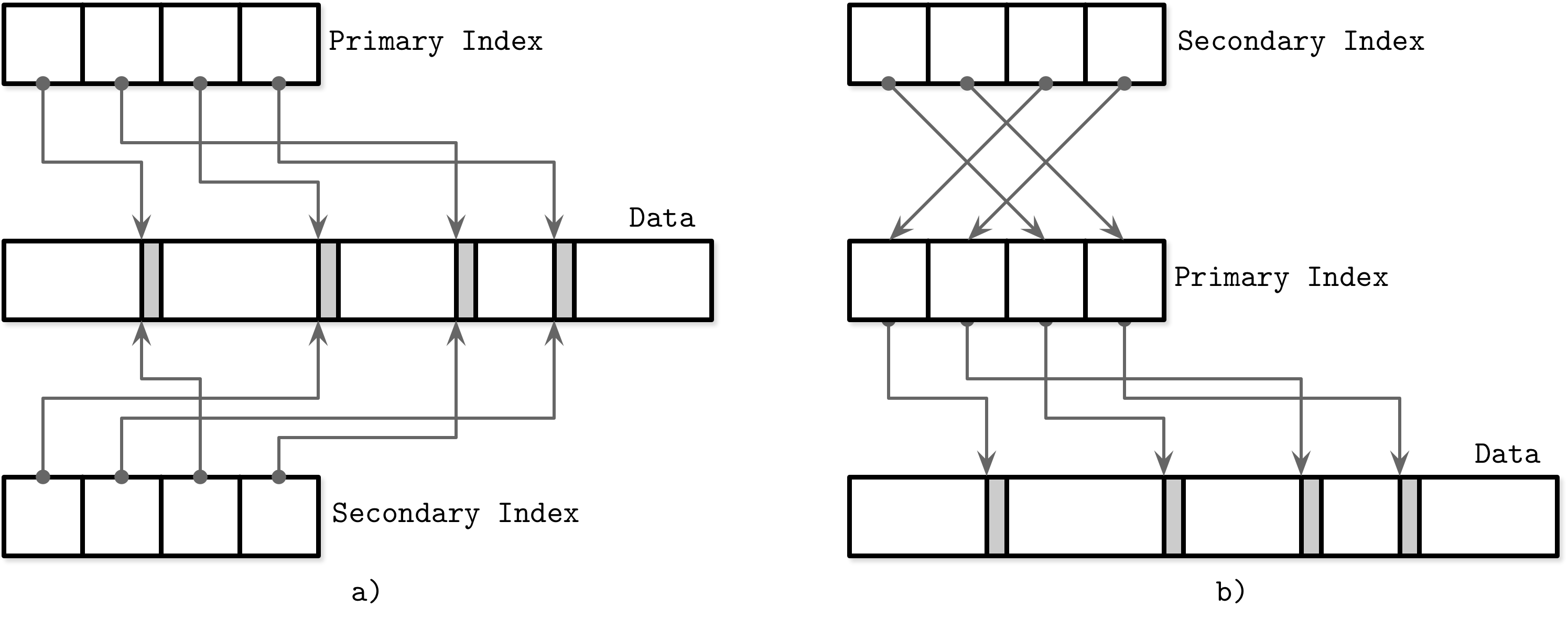
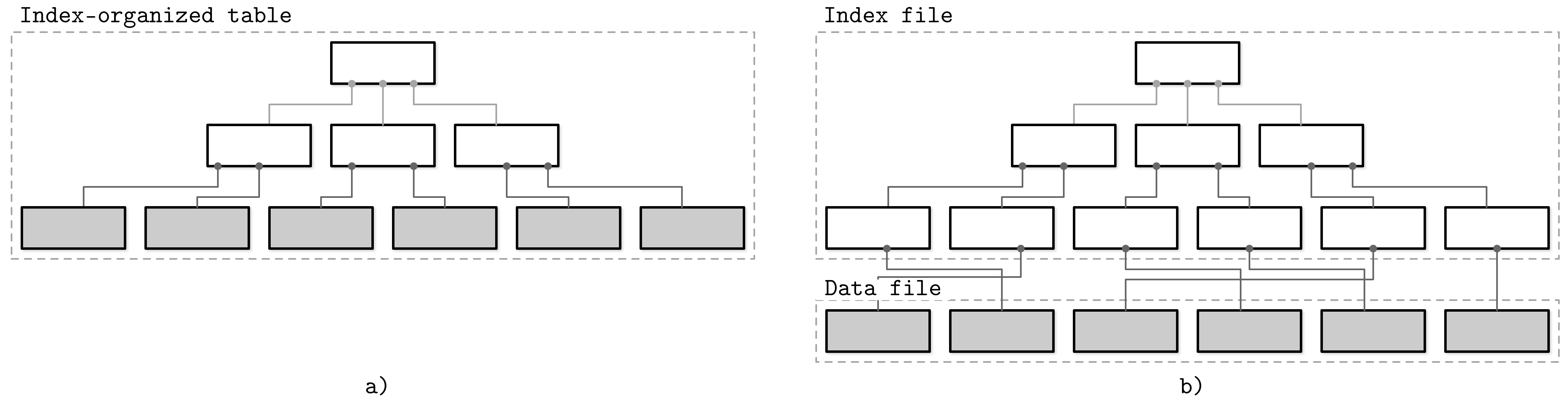 An index on a primary (data) file is called the primary index. In most cases we can also assume that the primary index is built over a primary key or a set of keys identified as primary. All other indexes are called secondary.
An index on a primary (data) file is called the primary index. In most cases we can also assume that the primary index is built over a primary key or a set of keys identified as primary. All other indexes are called secondary.
Secodandary Index
Secondary indexes can point directly to the data record, or simply store its primary key. A pointer to a data record can hold an offset to a heap file or an index-organized table. Multiple secondary indexes can point to the same record, allowing a single data record to be identified by different fields and located through different indexes. While primary index files hold a unique entry per search key, secondary indexes may hold several entries per search key
Clustered/Unclustered Indexes
If the order of data records follows the search key order, this index is called clustered (also known as clustering). Data records in the clustered case are usually stored in the same file or in a clustered file, where the key order is preserved. If the data is stored in a separate file, and its order does not follow the key order, the index is called nonclustered (sometimes called unclustered).
Buffering, Immutability, Ordering
Storage structures have three common variables: they use buffering (or avoid using it), use immutable (or mutable) files, and store values in order (or out of order)
Buffering This defines whether or not the storage structure chooses to collect a certain amount of data in memory before putting it on disk. Of course, every on-disk structure has to use buffering to some degree, since the smallest unit of data transfer to and from the disk is a block, and it is desirable to write full blocks. Here, we’re talking about avoidable buffering, something storage engine implementers choose to do. One of the first optimizations we discuss in this book is adding in-memory buffers to B-Tree nodes to amortize I/O costs (see “Lazy B-Trees”). However, this is not the only way we can apply buffering. For example, two-component LSM Trees (see “Two-component LSM Tree”), despite their similarities with B-Trees, use buffering in an entirely different way, and combine buffering with immutability.
Mutability (or immutability) This defines whether or not the storage structure reads parts of the file, updates them, and writes the updated results at the same location in the file. Immutable structures are append-only: once written, file contents are not modified. Instead, modifications are appended to the end of the file. There are other ways to implement immutability. One of them is copy-on-write (see “Copy-on-Write”), where the modified page, holding the updated version of the record, is written to the new location in the file, instead of its original location. Often the distinction between LSM and B-Trees is drawn as immutable against in-place update storage, but there are structures (for example, “Bw-Trees”) that are inspired by B-Trees but are immutable.
Ordering This is defined as whether or not the data records are stored in the key order in the pages on disk. In other words, the keys that sort closely are stored in contiguous segments on disk. Ordering often defines whether or not we can efficiently scan the range of records, not only locate the individual data records. Storing data out of order (most often, in insertion order) opens up for some write-time optimizations. For example, Bitcask (see “Bitcask”) and WiscKey (see “WiscKey”) store data records directly in append-only files.
#database